


Latest Facts











































Celebrity
Celebrity
Celebrity
Celebrity
Geography
Celebrity
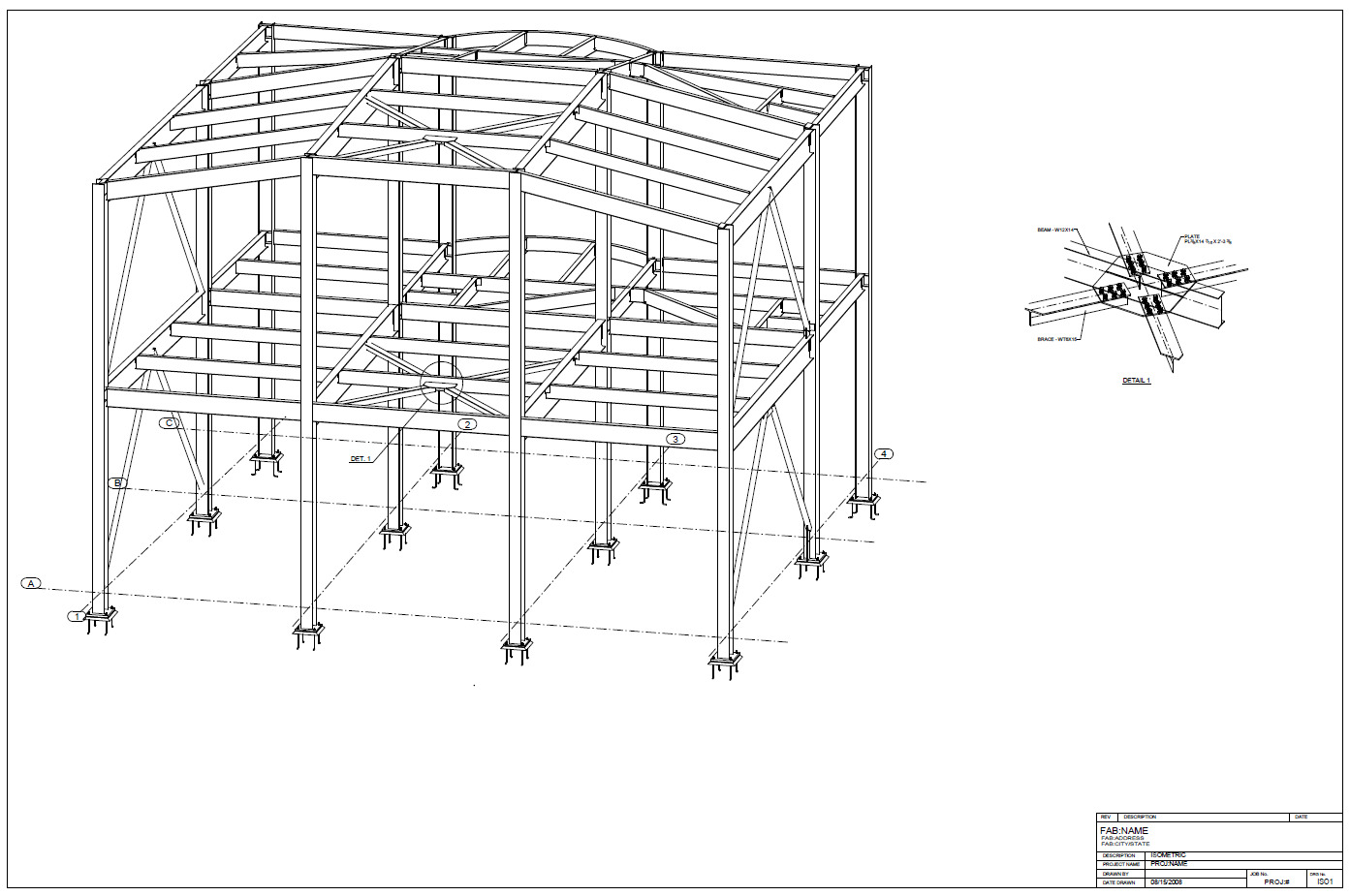
Engineering
Celebrity
Celebrity
Celebrity
Engineering
Celebrity
Celebrity
Celebrity
Celebrity
Celebrity
Celebrity
Engineering
Celebrity
Celebrity
Celebrity
Geography
Celebrity
Celebrity
Celebrity
Engineering
Celebrity
Celebrity
Celebrity
Celebrity
Celebrity
Celebrity
Engineering
Celebrity
Celebrity
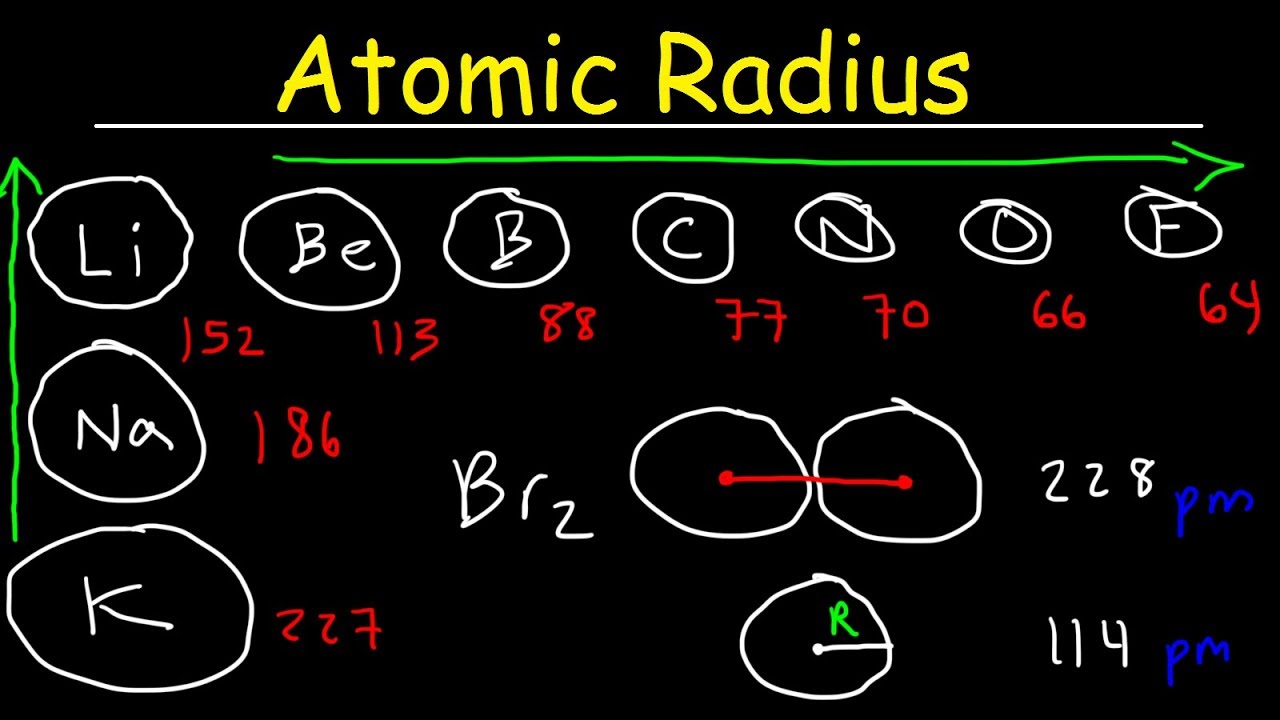
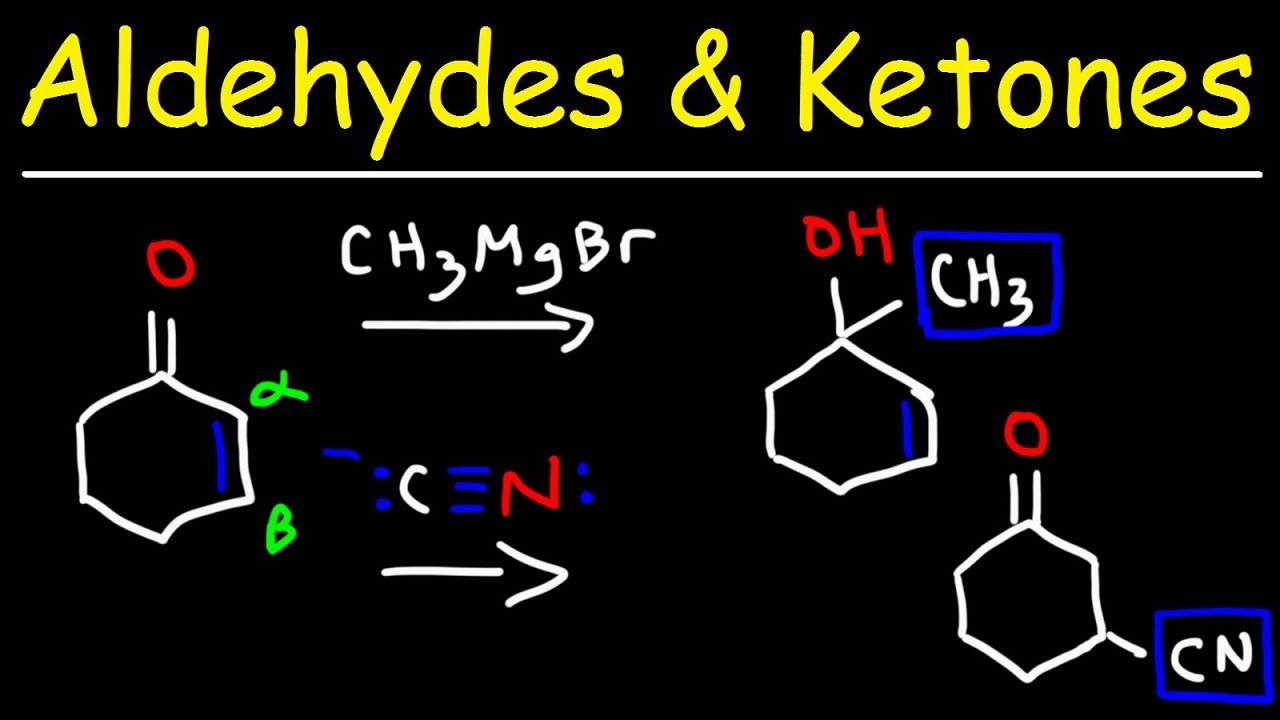
Chemistry
Biology
Engineering
Chemistry
Chemistry
Celebrity
Celebrity
Biology
Chemistry
Engineering
Chemistry
Chemistry
Popular Facts
























30 Exotic Plants to Cultivate in Your Garden
Imagine stepping into your garden and feeling like you’ve been transported to a far-off land. Exotic plants can turn any ordinary backyard into a lush paradise, filled with vibrant colors […]









