

Latest Facts










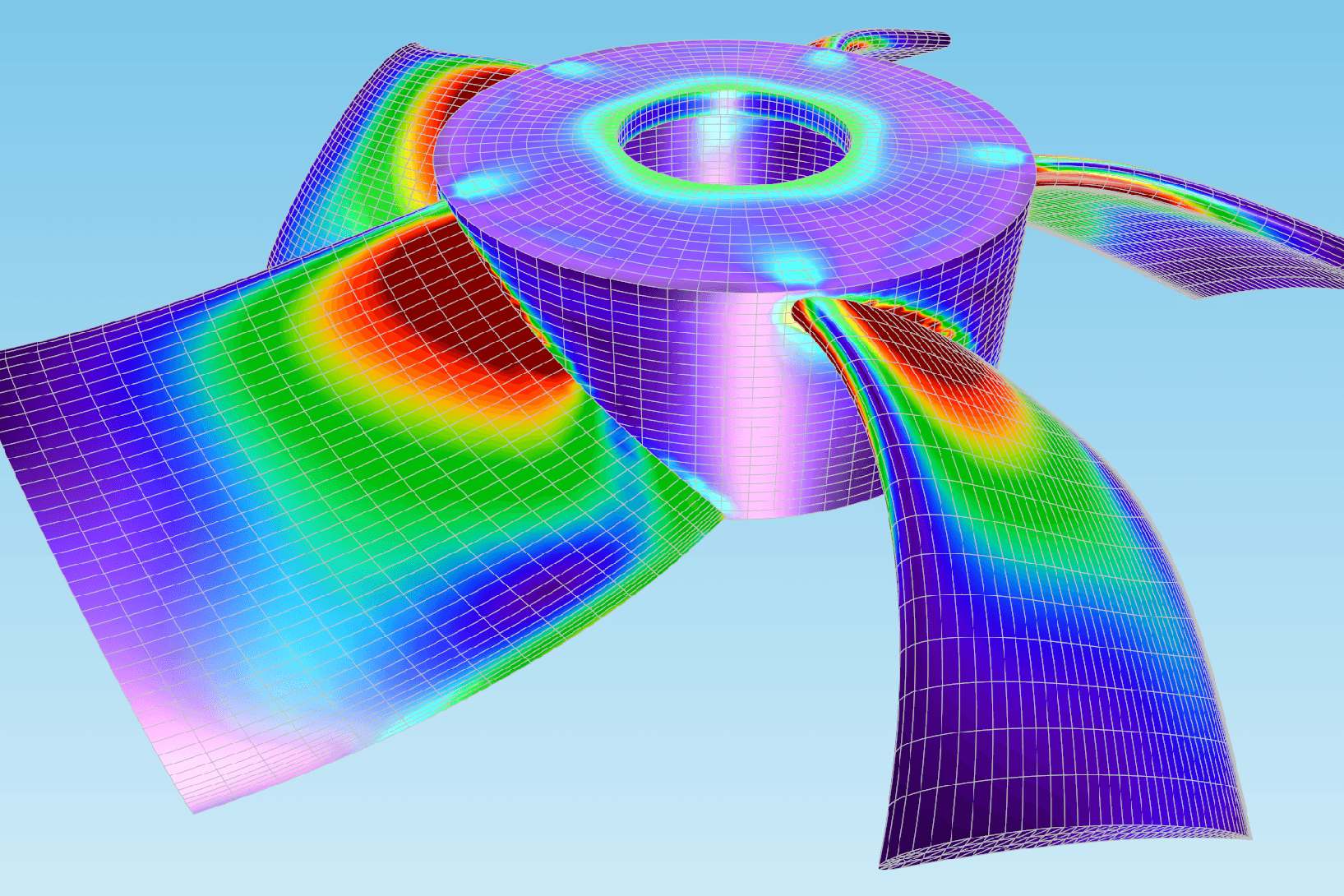







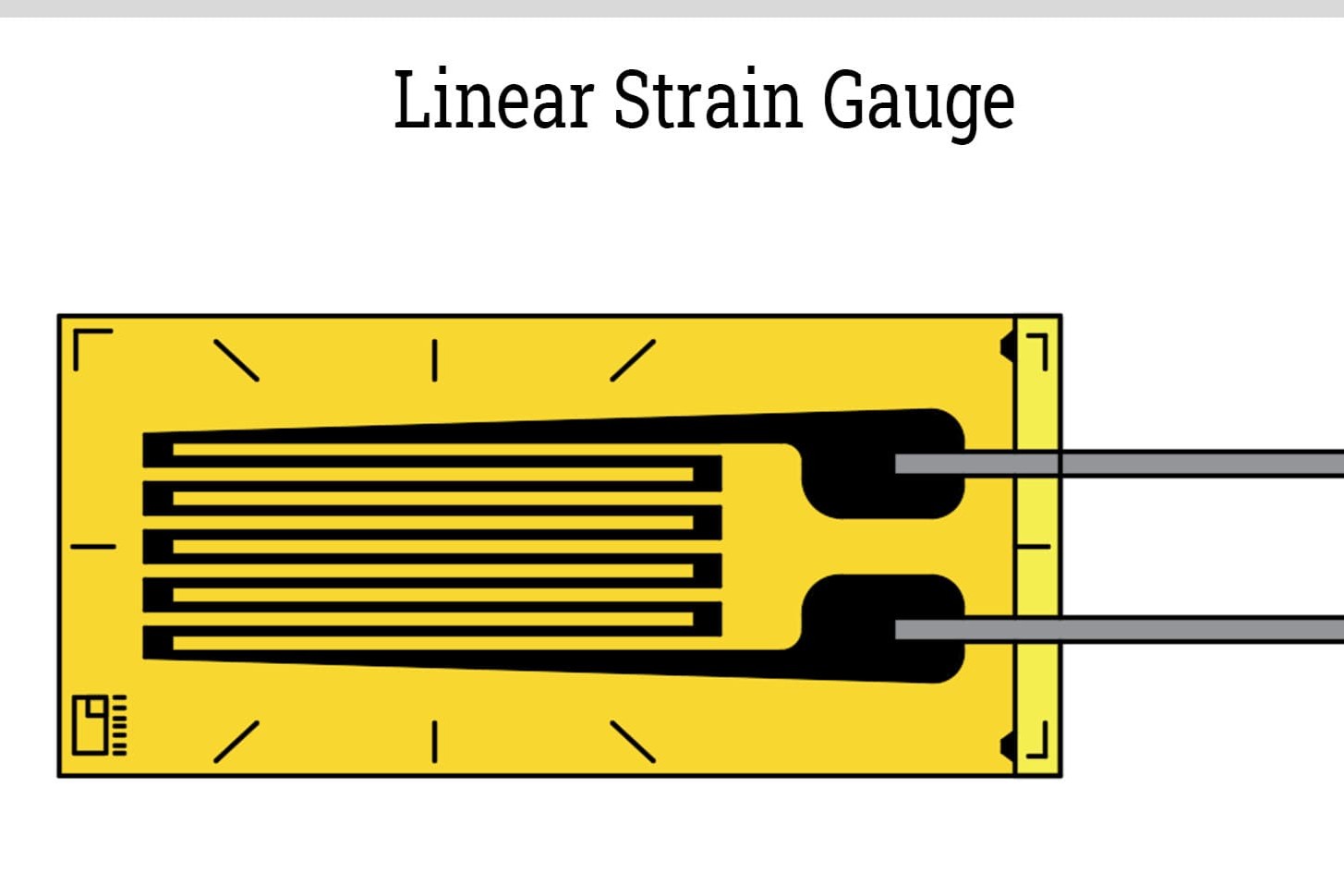



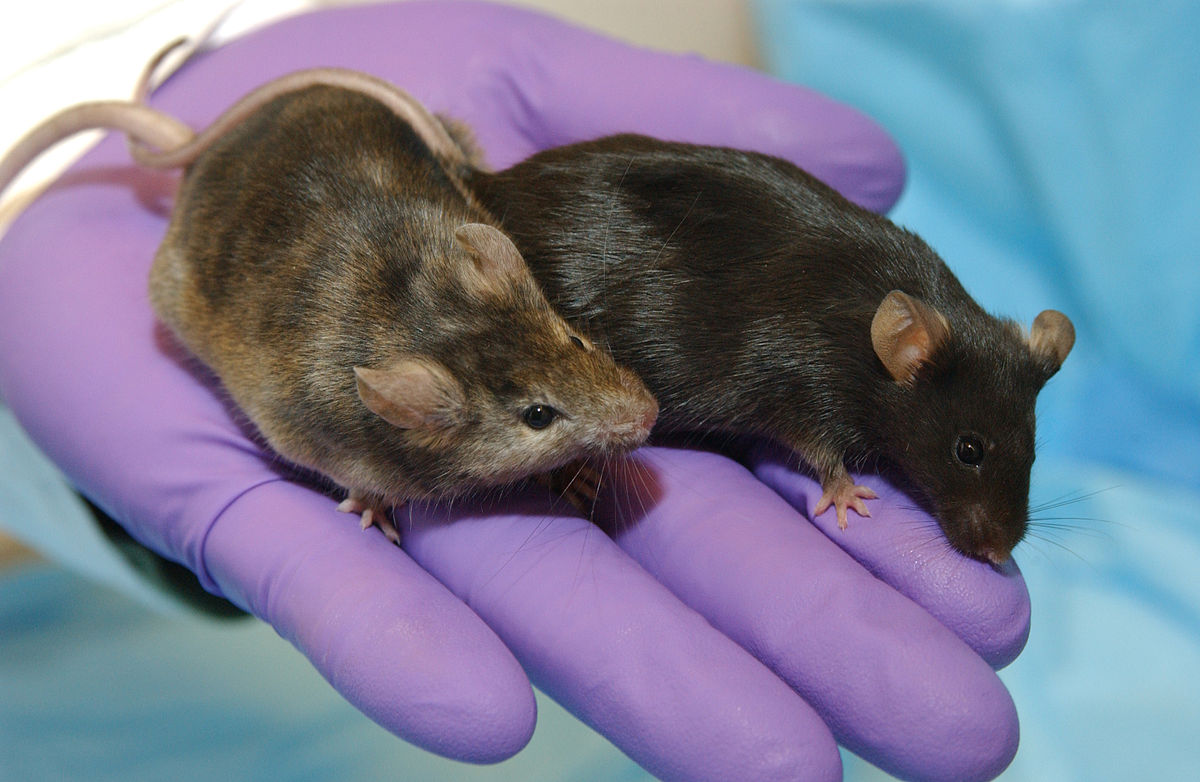
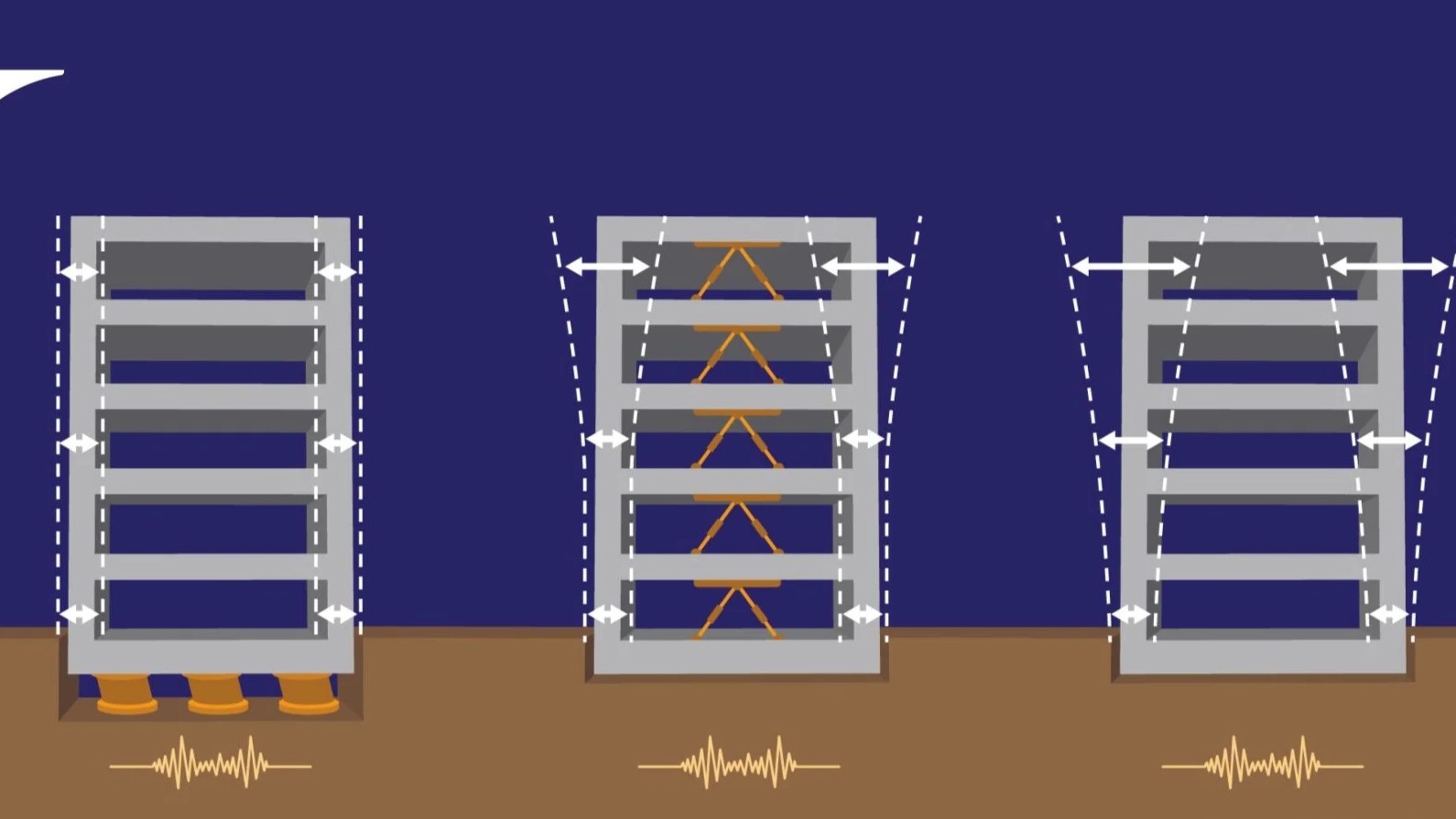


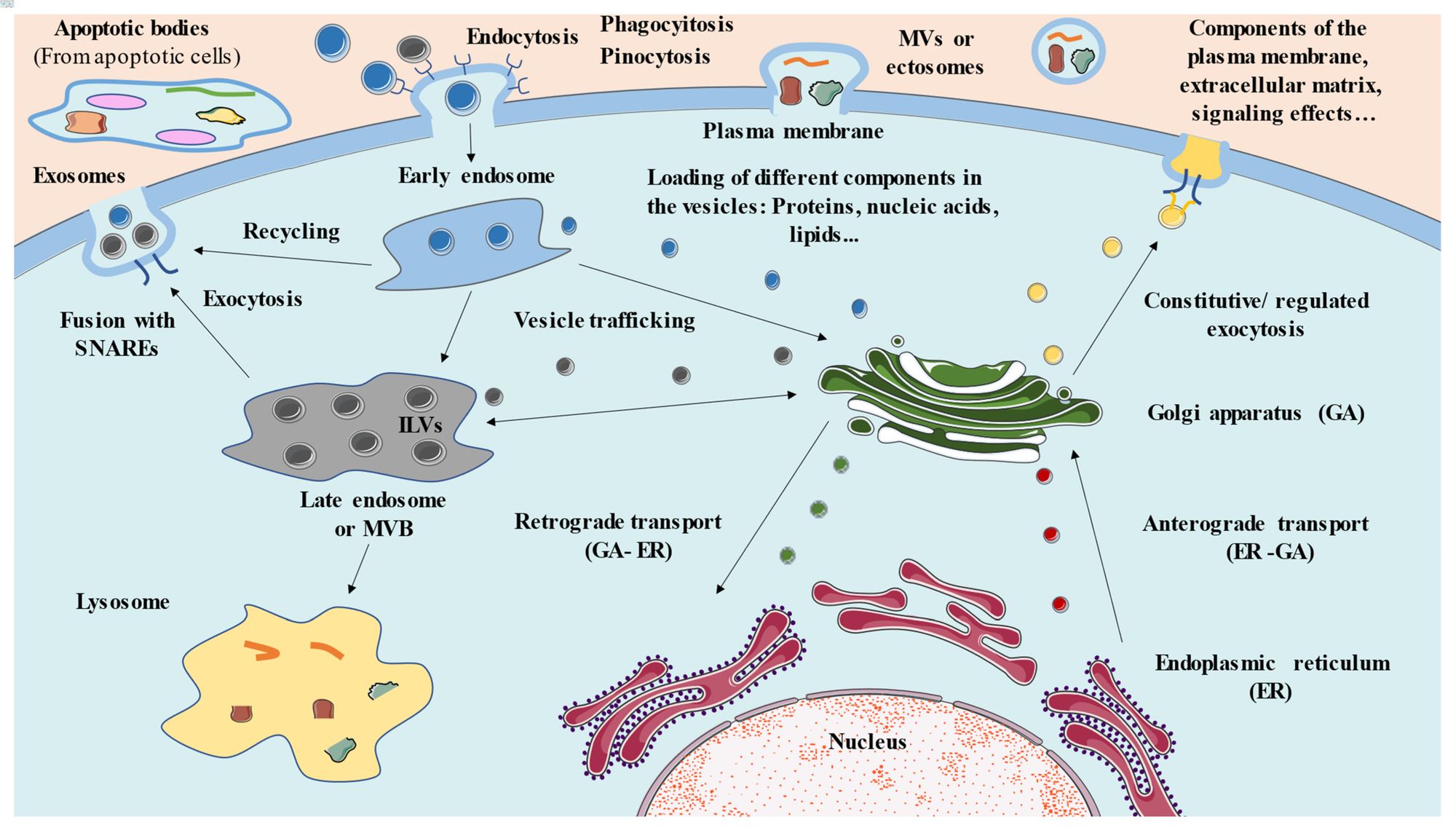
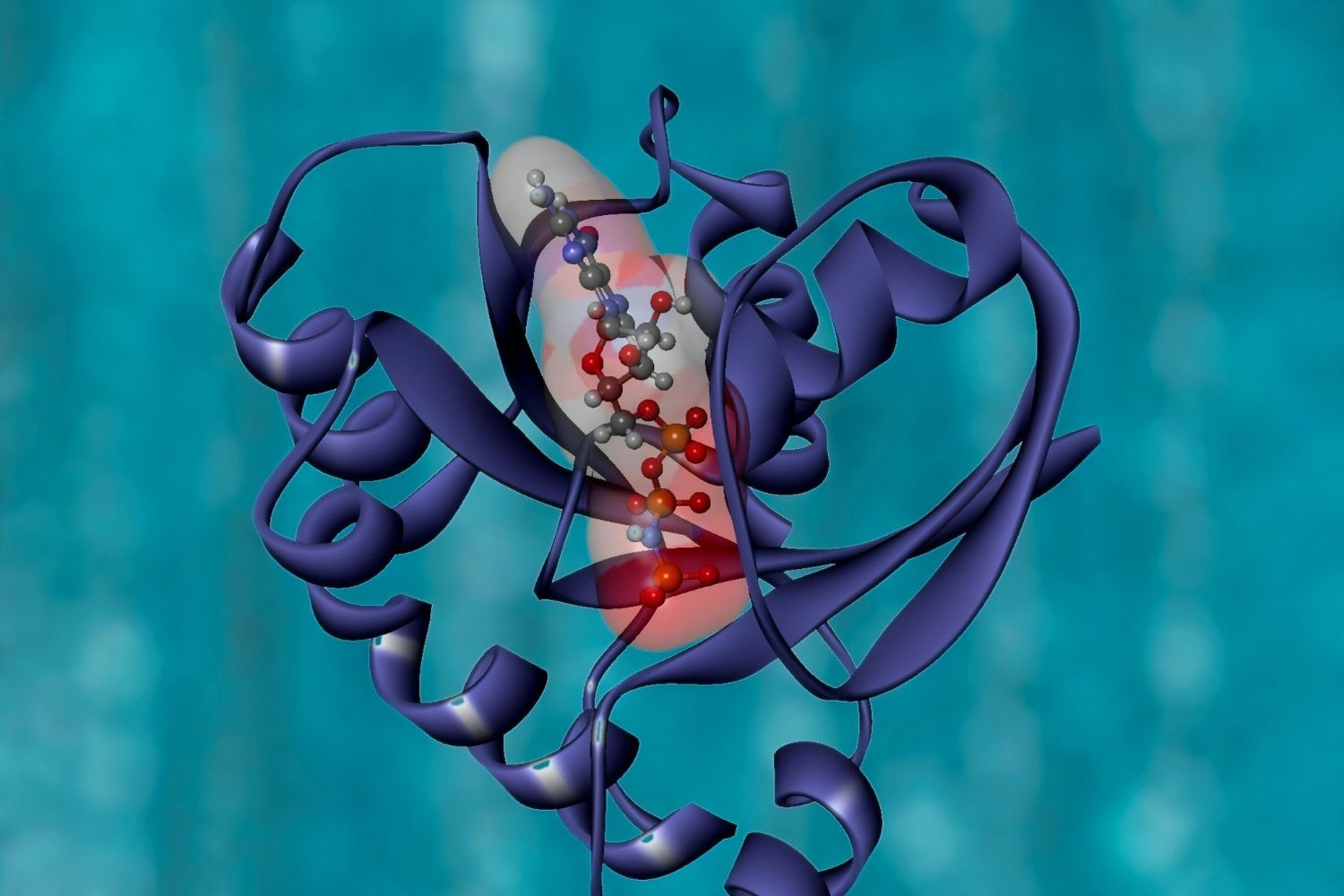
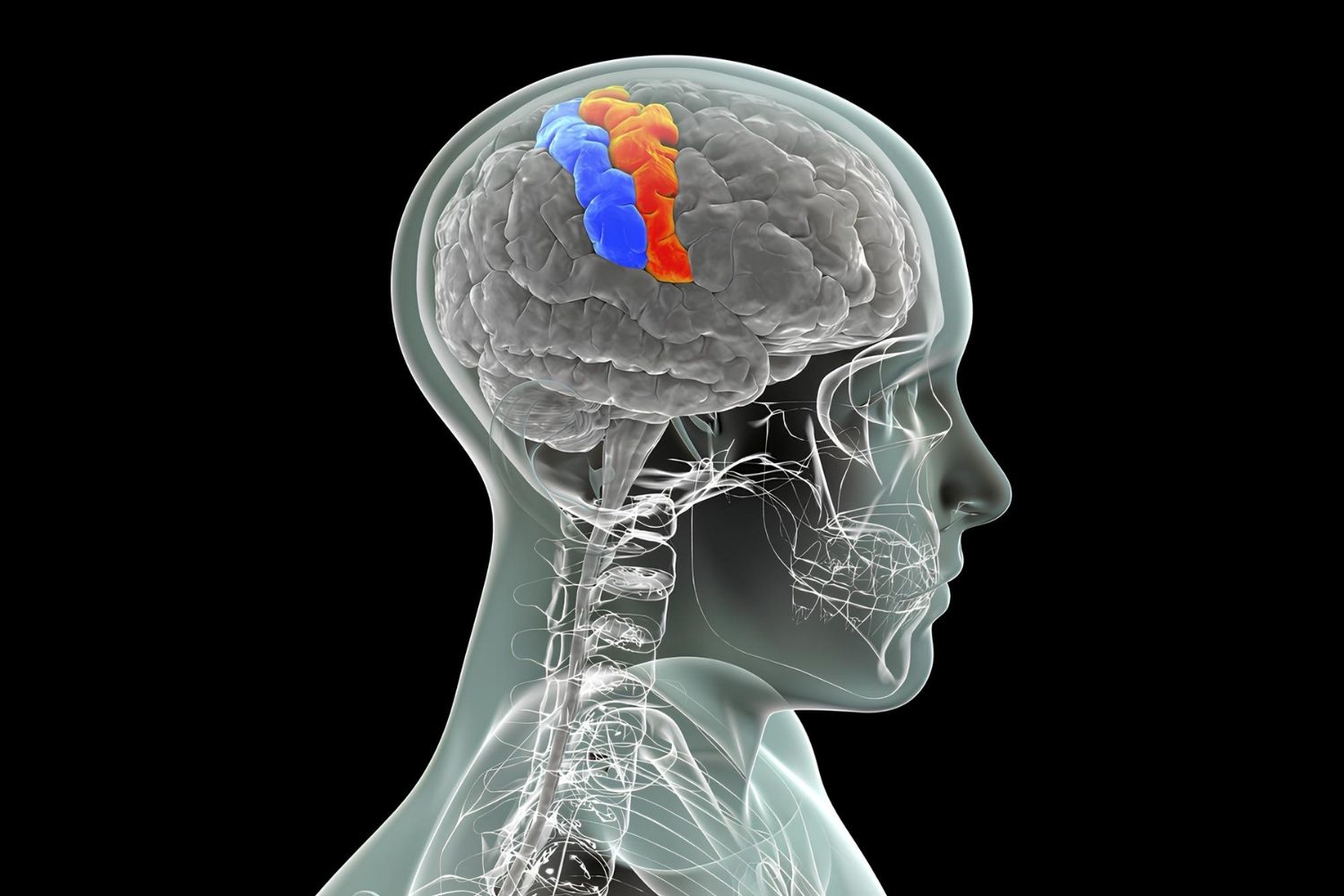
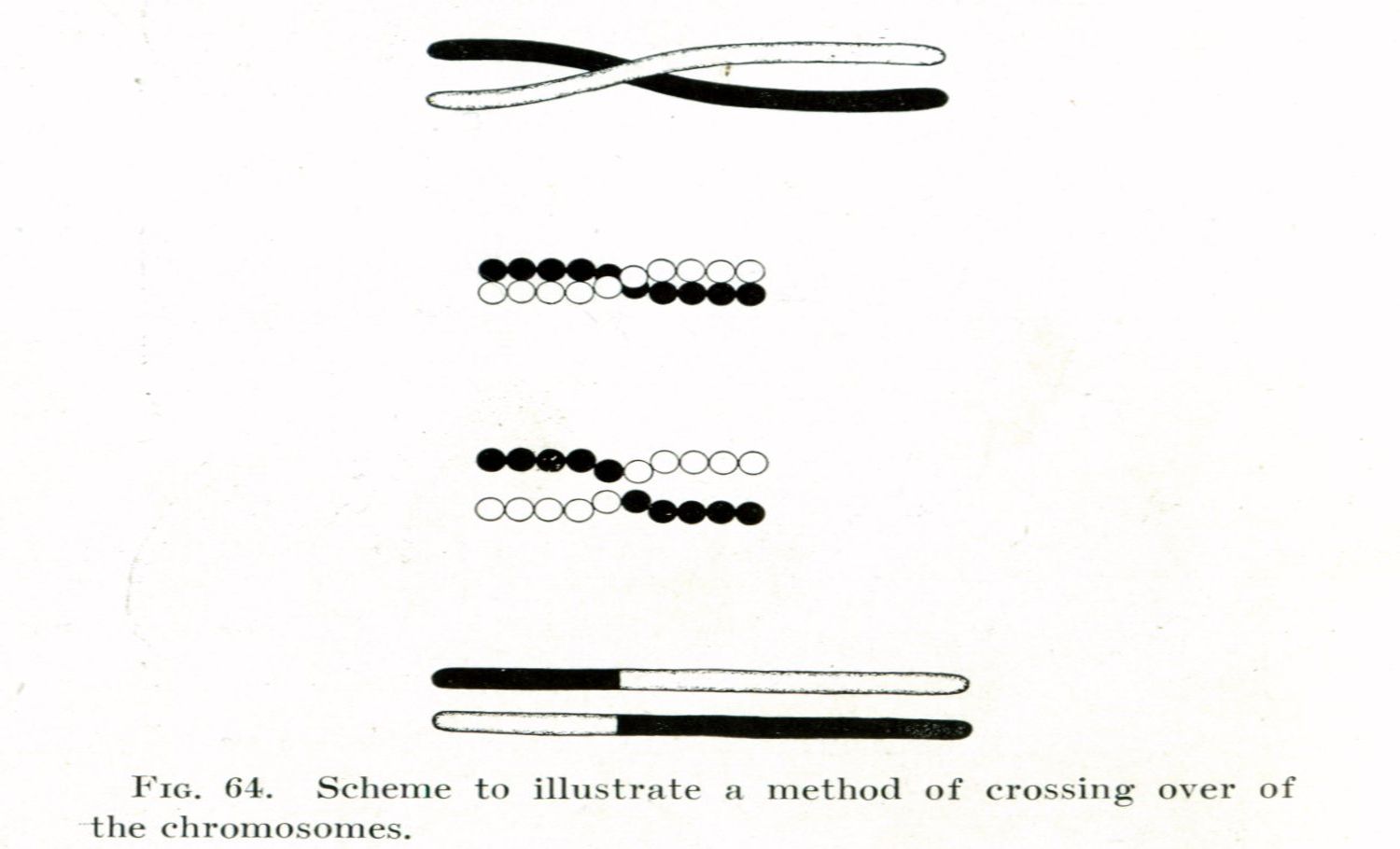
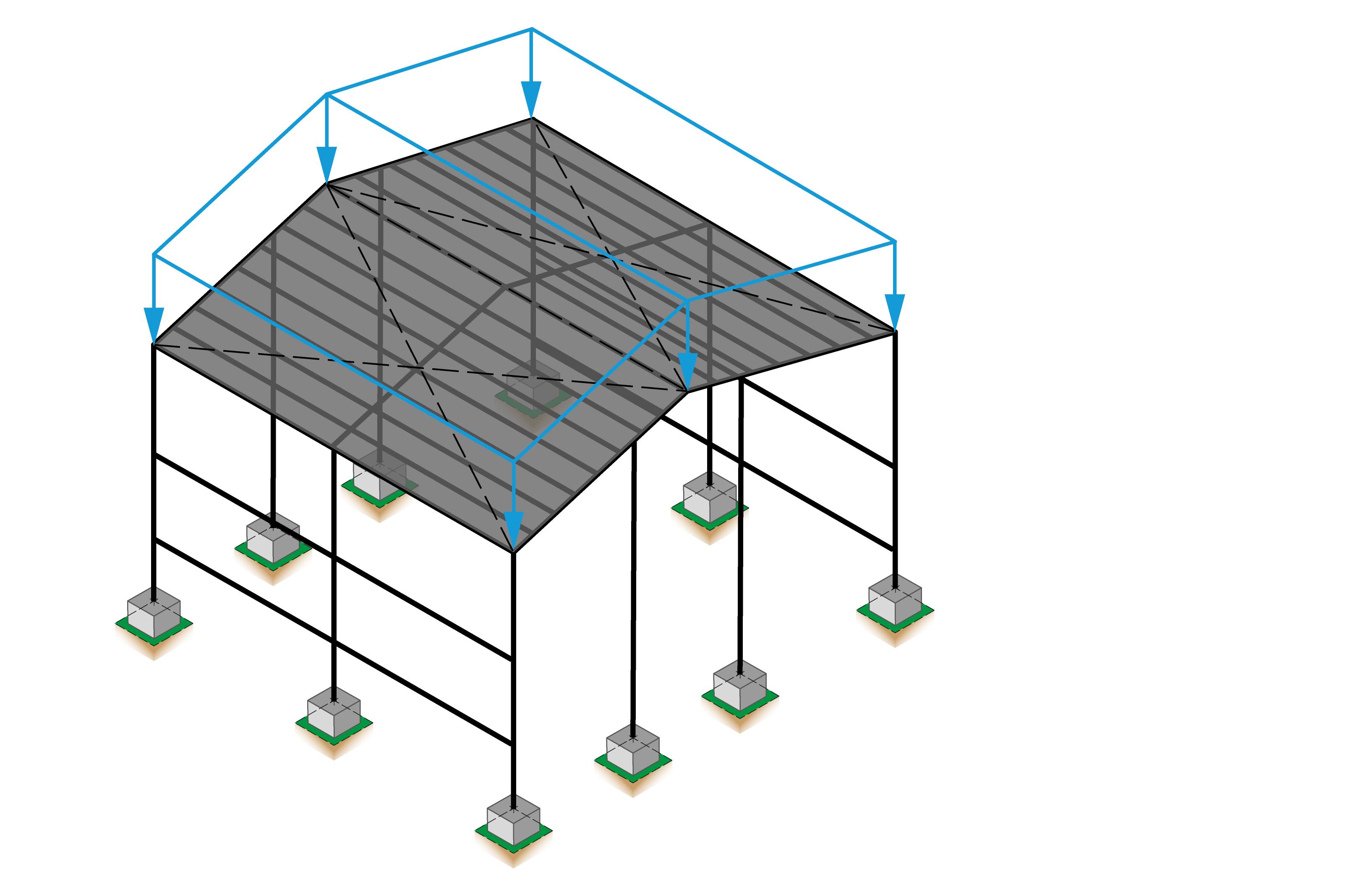

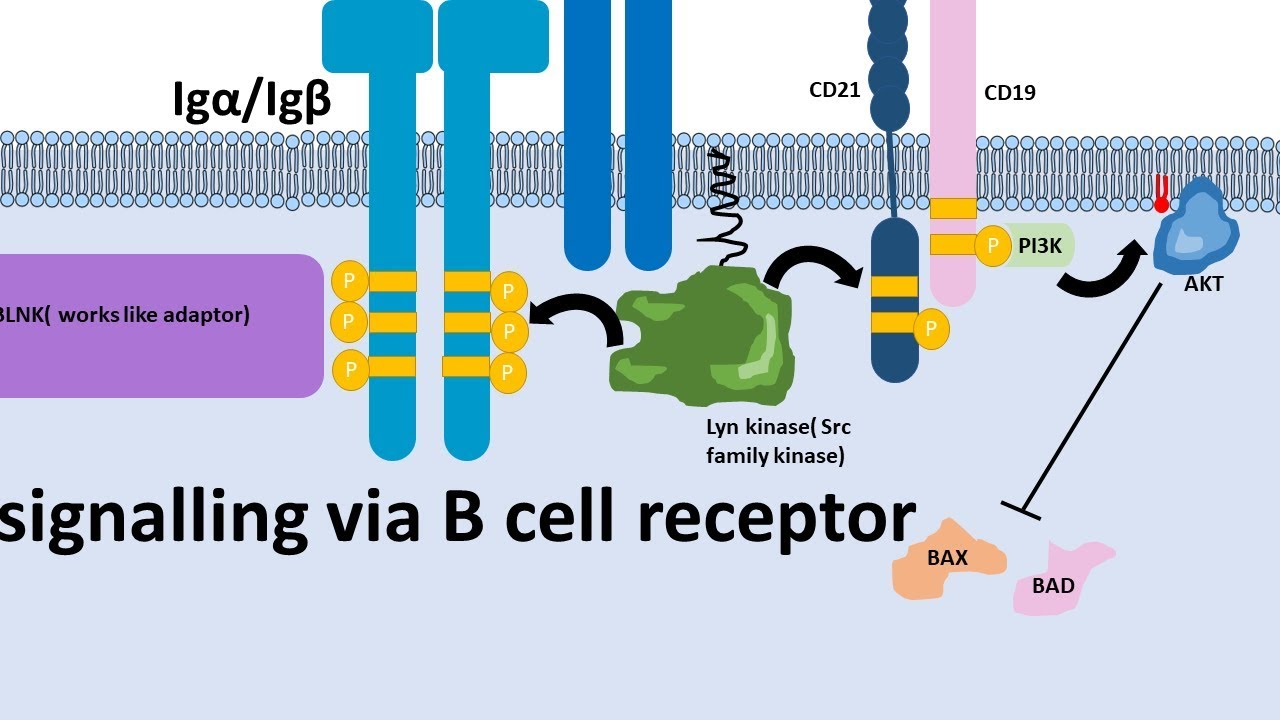

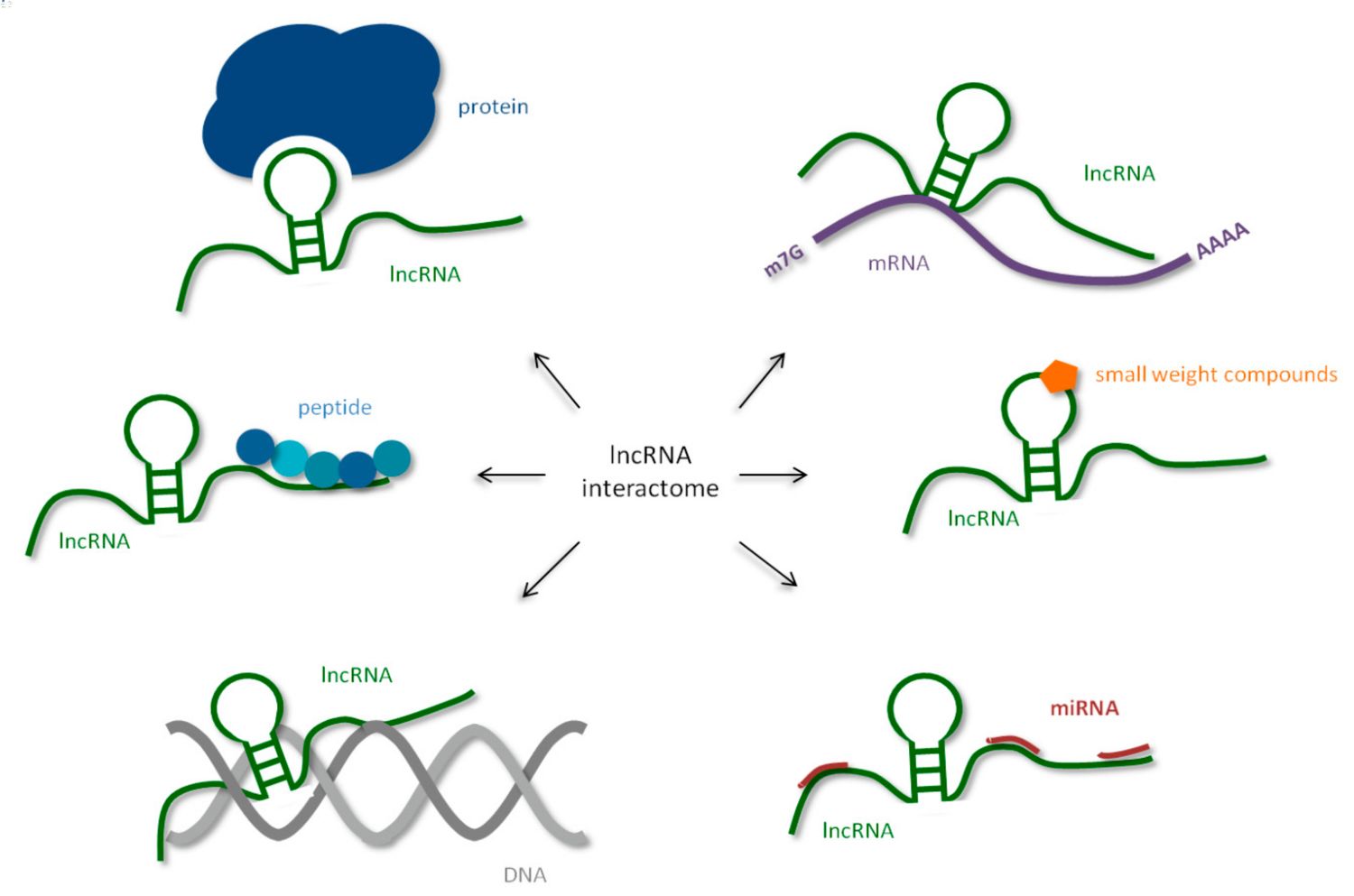
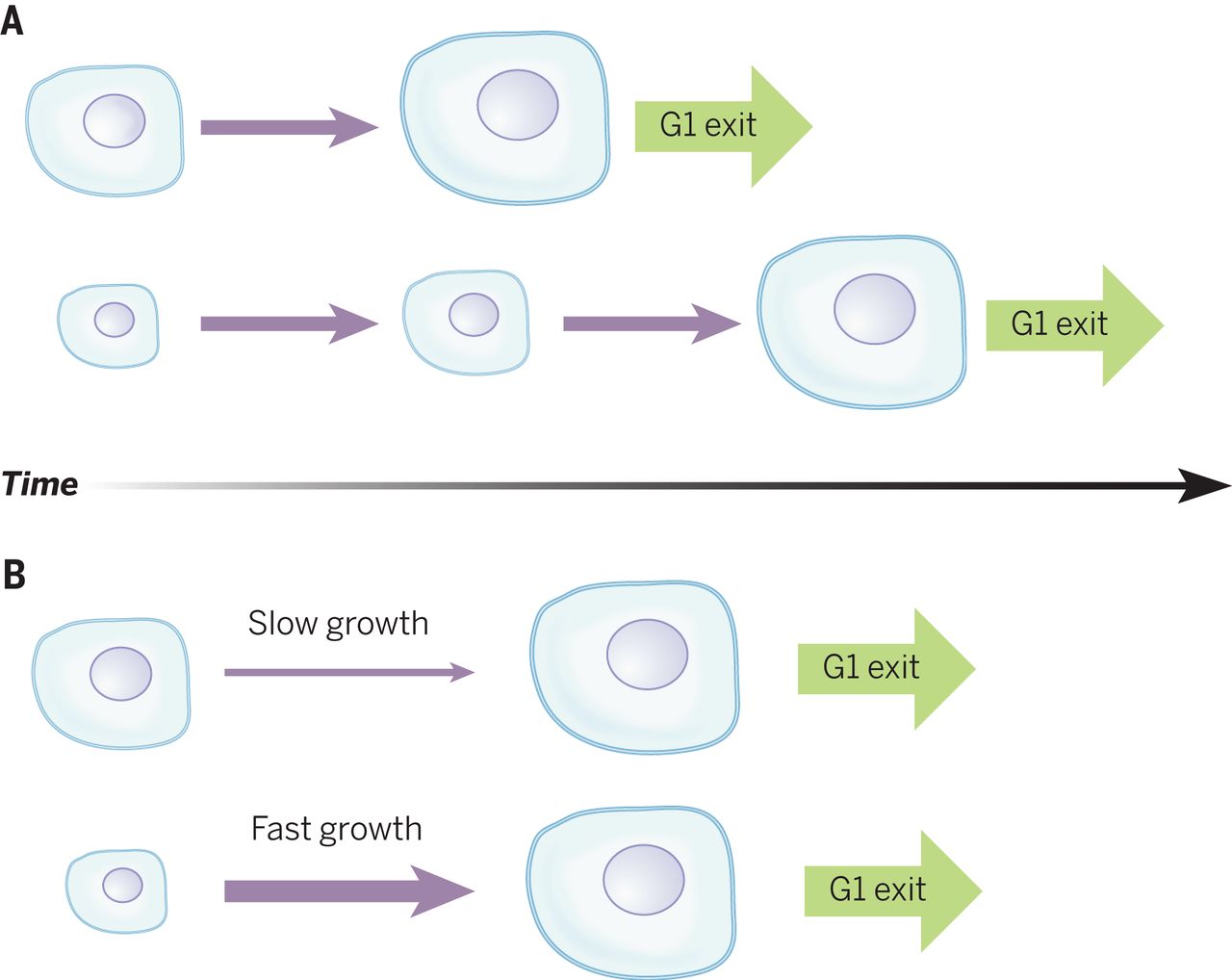






Engineering
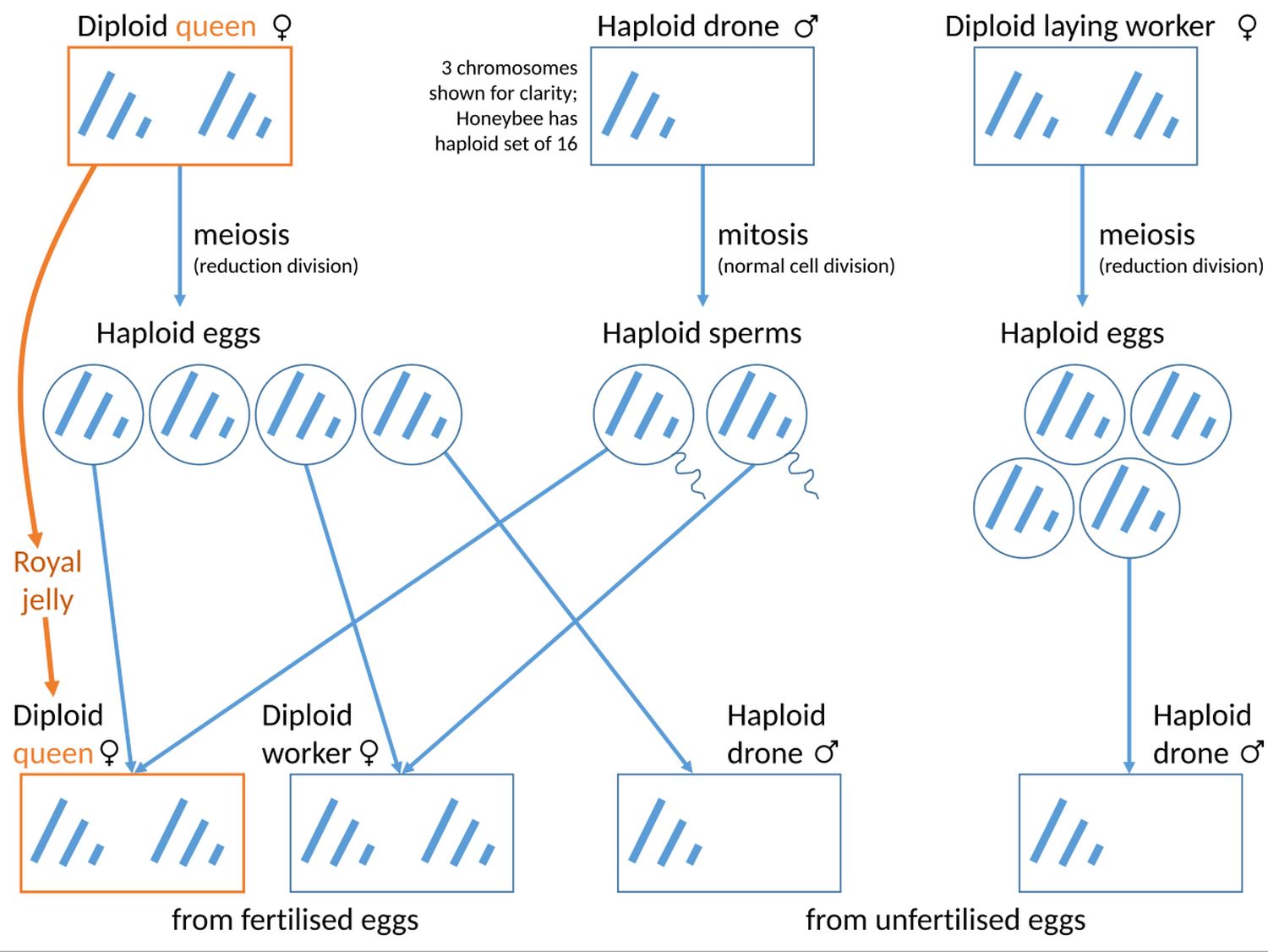
Biology
Biology
Engineering
Celebrity
Biology
Biology
Engineering
Celebrity
Biology
Engineering
Biology
Biology
Engineering
Celebrity
Biology
Engineering
Biology
Biology
Biology
Engineering
Celebrity
Engineering
Celebrity
Engineering
Biology
Biology
Celebrity
Engineering
Engineering
Engineering
Celebrity
Biology
Biology
Engineering
Engineering
Celebrity
Engineering
Celebrity
Biology
Engineering
Engineering
Celebrity
Engineering
Engineering
Popular Facts
























15 Top Movies About Royalty
Who doesn’t love a good royal drama? From the grandeur of palaces to the intricate politics of court life, movies about royalty offer a fascinating glimpse into a world of […]









